简介
triplet loss是三元组损失,用于区分差异较小的样本,一般可以用于标签样本较少的数据集中。给定三个样本,anchor,positive,negative sample,希望通过训练,使得anchor与positive的距离很大,而与negative的距离很小,loss function形式如下
$$L = \sum\limits_{i = 1}^N {\max (\left| {f(x_i^a) - f(x_i^p)} \right|_2^2 - \left| {f(x_i^a) - f(x_i^n)} \right|_2^2 + \alpha ,0)}$$
参考链接
- 在这里给出参考的一些链接,表示感谢。
- 讲述mxboard可视化:https://medium.com/apache-mxnet/mxboard-mxnet-data-visualization-2eed6ae31d2c
- 本文参考的代码:https://github.com/SpikeKing/triplet-loss-gluon
- 本文修改后代码:https://github.com/littletomatodonkey/mnist_triplet_loss
代码讲解
- mxnet中直接封装了triplet loss,可以直接使用,代码主要参考了:https://github.com/SpikeKing/triplet-loss-gluon中的内容,我对其做了一些修改,修改后的代码上传到自己的github上了:https://github.com/littletomatodonkey/mnist_triplet_loss
Dataset定义
主要就是定义一个pair的数组,每个单元包含了anchor、positive与negative sample,这里需要注意的是,anchor与positive sample的label需要是相同的,而anchor与negative sample的label不能使相同的。
class TripletDataset(gluon.data.dataset.Dataset): def __init__(self, rd, rl, transform=None): self.__rd = rd # 原始数据 self.__rl = rl # 原始标签 self._data = None self._label = None self._transform = transform self._get_data() def __getitem__(self, idx): if self._transform is not None: return self._transform(self._data[idx], self._label[idx]) return self._data[idx], self._label[idx] def __len__(self): return len(self._label) def _get_data(self): label_list = np.unique(self.__rl) digit_indices = [np.where(self.__rl == i)[0] for i in label_list] tl_pairs = self.create_pairs(self.__rd, digit_indices, len(label_list)) self._data = tl_pairs self._label = np.ones(tl_pairs.shape[0]) @staticmethod def create_pairs(x, digit_indices, num_classes): x = x.asnumpy() # 转换数据格式 pairs = [] n = min([len(digit_indices[d]) for d in range(num_classes)]) - 1 # 最小类别数 for d in range(num_classes): for i in range(n): np.random.shuffle(digit_indices[d]) z1, z2 = digit_indices[d][i], digit_indices[d][i + 1] inc = random.randrange(1, num_classes) dn = (d + inc) % num_classes z3 = digit_indices[dn][i] pairs += [[x[z1], x[z2], x[z3]]] return np.asarray(pairs)
evaluation
该部分计算准确率,对于特定的tuple sample,满足其loss=0的时候,则说明这个tuple的区分是正确的,计算函数如下
def evaluate_net(model, test_data, ctx=mx.cpu() ): triplet_loss = gluon.loss.TripletLoss(margin=0) sum_correct = 0.0 sum_all = 0 rate = 0.0 for i, (data, _) in enumerate(test_data): data = data.as_in_context(ctx) anc_ins, pos_ins, neg_ins = data[:, 0], data[:, 1], data[:, 2] inter1 = model(anc_ins) # 训练的时候组合 inter2 = model(pos_ins) inter3 = model(neg_ins) # print( inter1.shape ) loss = triplet_loss(inter1, inter2, inter3) loss = loss.asnumpy() n_all = loss.shape[0] n_correct = np.sum(np.where(loss == 0, 1, 0)) sum_correct += n_correct sum_all += n_all rate = sum_correct / sum_all # print('accuracy : %.4f (%s / %s)' % (rate, sum_correct, sum_all)) return rate
train
主要就是导入数据,生成triplet training data,之后使用sgd进行BP迭代训练即可。
ctx = mx.gpu() batch_size = 1024 random.seed(47) mnist_data_dir = '../dataset/mnist' mnist_train = gluon.data.vision.MNIST(train=True, root=mnist_data_dir) # load train data tr_data = mnist_train._data.reshape((-1, 28 * 28)) tr_label = mnist_train._label # 标签 mnist_test = gluon.data.vision.MNIST(train=False, root=mnist_data_dir) # load test data te_data = mnist_test._data.reshape((-1, 28 * 28)) te_label = mnist_test._label def transform(data_, label_): return data_.astype(np.float32) / 255., label_.astype(np.float32) train_data = gluon.data.DataLoader( TripletDataset(rd=tr_data, rl=tr_label, transform=transform), batch_size, shuffle=True) test_data = gluon.data.DataLoader( TripletDataset(rd=te_data, rl=te_label, transform=transform), batch_size, shuffle=True) base_net = gluon.nn.Sequential() with base_net.name_scope(): base_net.add(gluon.nn.Dense(256, activation='relu')) base_net.add(gluon.nn.Dense(128, activation='relu')) base_net.collect_params().initialize(mx.init.Uniform(scale=0.1), ctx=ctx, force_reinit=True) triplet_loss = gluon.loss.TripletLoss() # TripletLoss损失函数 trainer_triplet = gluon.Trainer(base_net.collect_params(), 'sgd', {'learning_rate': 0.03}) for epoch in range(100): curr_loss = 0.0 for i, (data, _) in enumerate(train_data): data = data.as_in_context(ctx) anc_ins, pos_ins, neg_ins = data[:, 0], data[:, 1], data[:, 2] with autograd.record(): inter1 = base_net(anc_ins) inter2 = base_net(pos_ins) inter3 = base_net(neg_ins) loss = triplet_loss(inter1, inter2, inter3) # Triplet Loss loss.backward() trainer_triplet.step(batch_size) curr_loss = mx.nd.mean(loss).asscalar() # print('Epoch: %s, Batch: %s, Triplet Loss: %s' % (epoch, i, curr_loss)) if epoch % 10 == 0: val_acc = evaluate_net(base_net, test_data, ctx=ctx) print('Epoch: %s, Triplet Loss: %s, validation accuracy : %f' % (epoch, curr_loss, val_acc))
visualization
- 可以使用mxboard进行方便地可视化,但是这个是需要使用tensorboard的,因此需要首先安装tensorflow与tensorboard的(因为只需要做日志记录,因此如果不需要使用tf跑深度学习代码的话,可以直接安装cpu版本的tensorflow即可)
保存结果到日志的代码如下,这里只显示了1000个sample。
trans_te_data, trans_te_label = transform(te_data, te_label) trans_te_data = trans_te_data[0:1000] trans_te_label = trans_te_label[0:1000] trans_te_label = mx.nd.array( trans_te_label ) # tb_projector(trans_te_data.asnumpy(), trans_te_label, os.path.join(ROOT_DIR, 'logs', 'origin')) # 如果需要看初始时刻的embedding情况,可以强制初始化 # base_net.collect_params().initialize(mx.init.Uniform(scale=0.1), ctx=ctx, force_reinit=True) trans_te_res = base_net(trans_te_data.as_in_context( context=ctx )) # 转换成4D数据 NCHW trans_te_data = trans_te_data.reshape( (-1,28,28)) trans_te_data = mx.nd.expand_dims( trans_te_data, axis=(1) ) label_str = [str(int(idx)) for idx in trans_te_label.asnumpy()] with SummaryWriter(logdir='./logs') as sw: sw.add_image(tag='mnists', image=trans_te_data) sw.add_embedding(tag='mnist_codes', embedding=trans_te_res, images=trans_te_data, labels=label_str)
结果
下面显示一些使用mxboard可视化出来的图像。
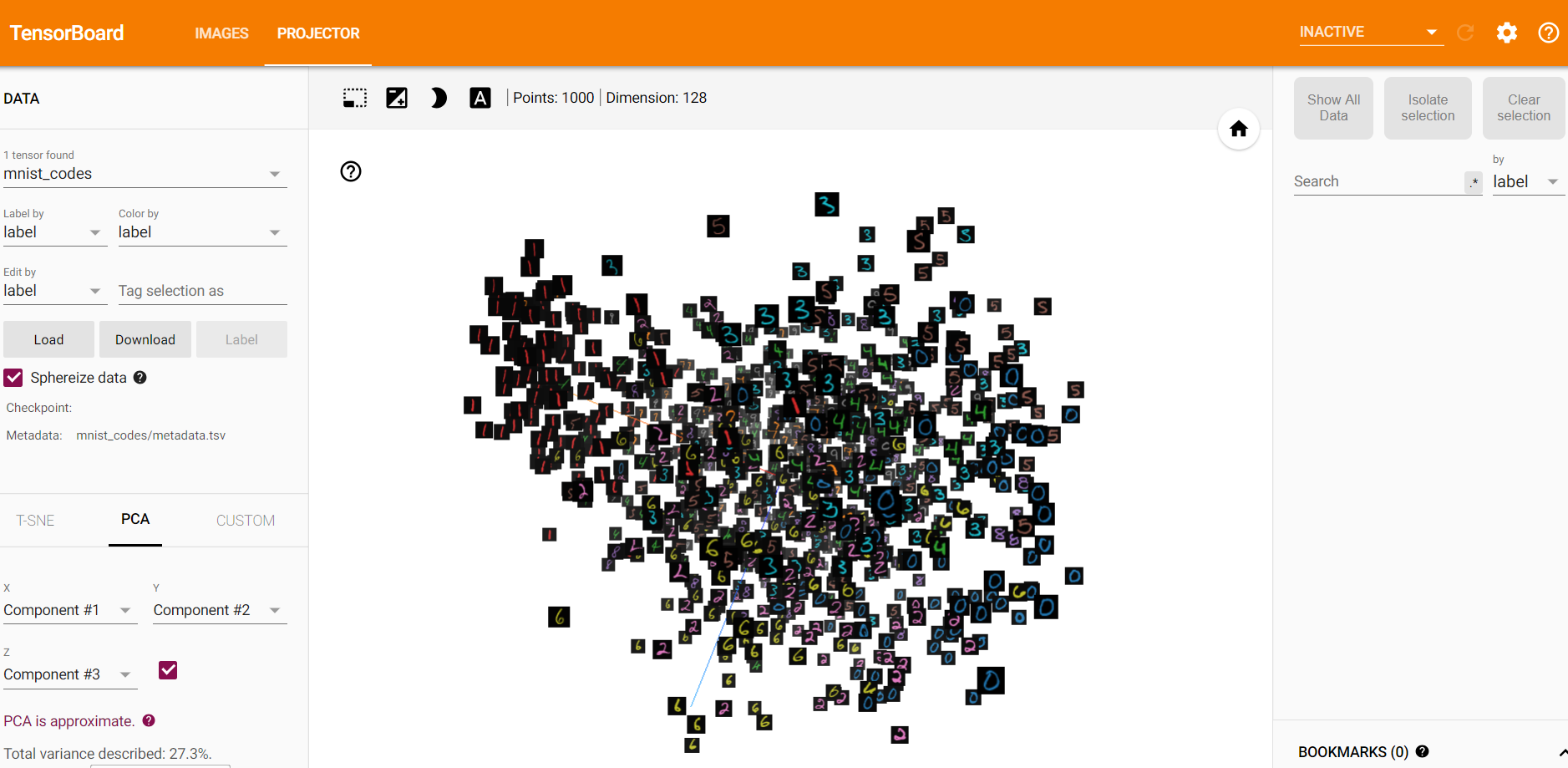
初始时刻,模型得到的embedding参数,使用PCA可视化的图像。
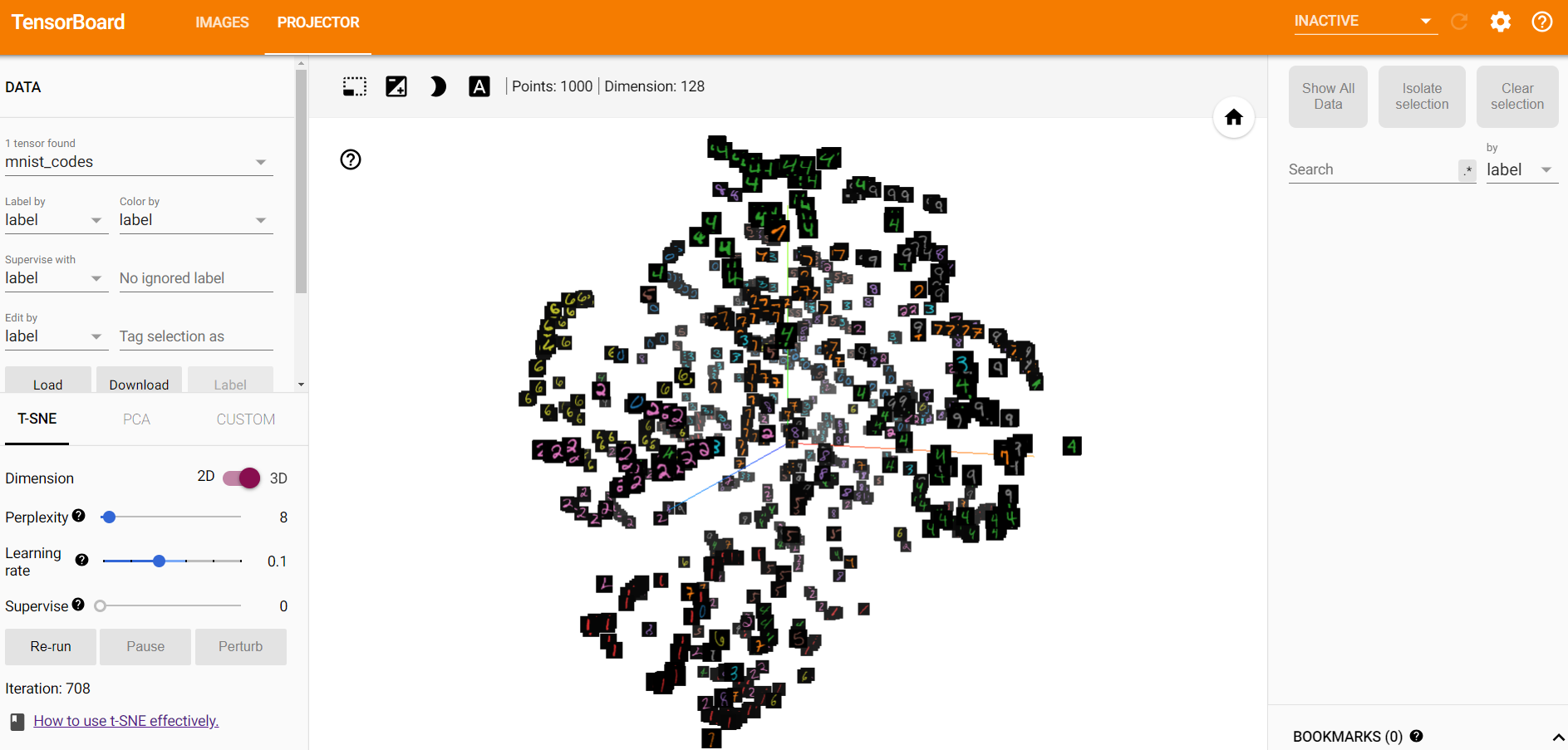
- 初始时刻,模型得到的embedding参数,使用t-SNE可视化的图像。
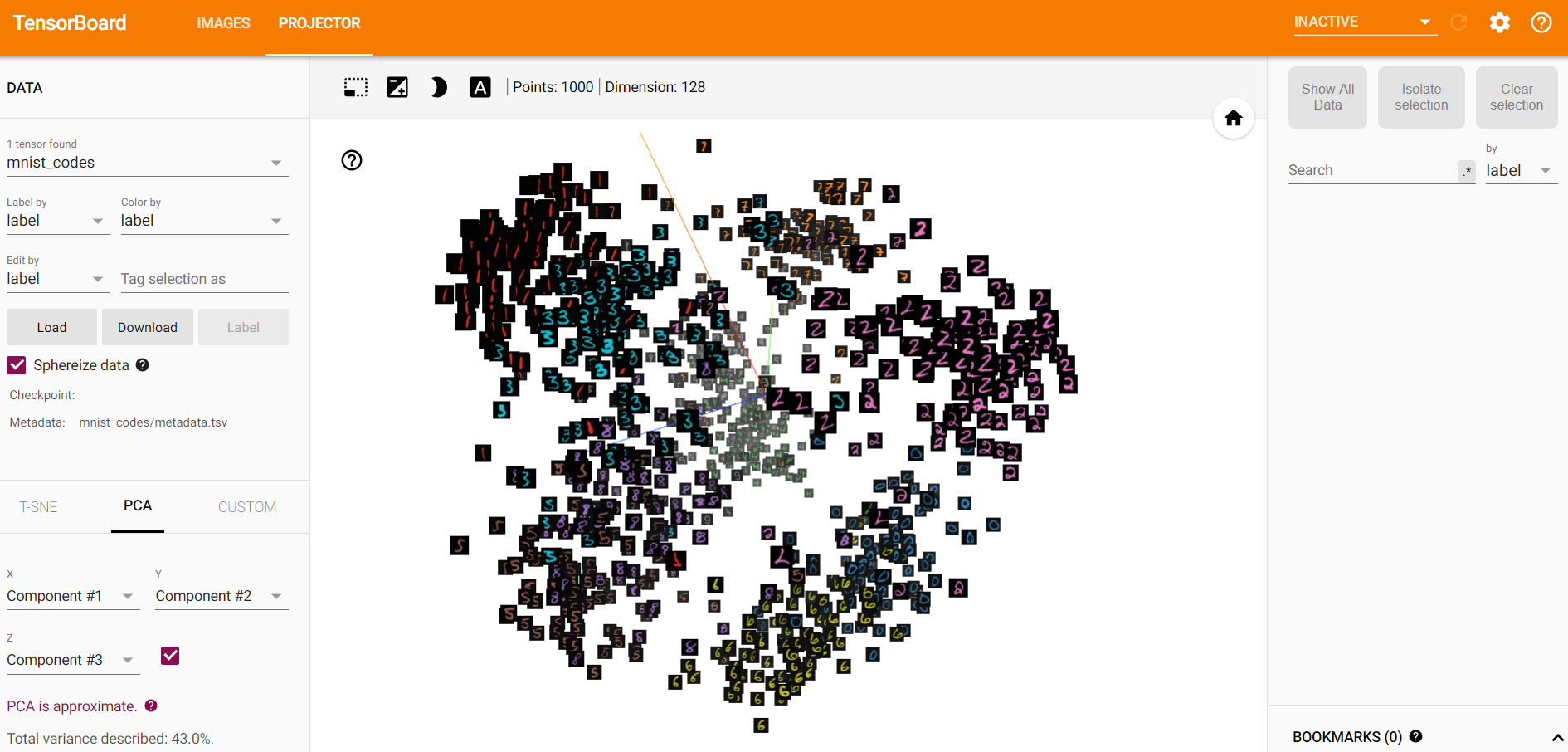
- 训练一段时间后,模型得到的embedding参数,使用PCA可视化的图像。
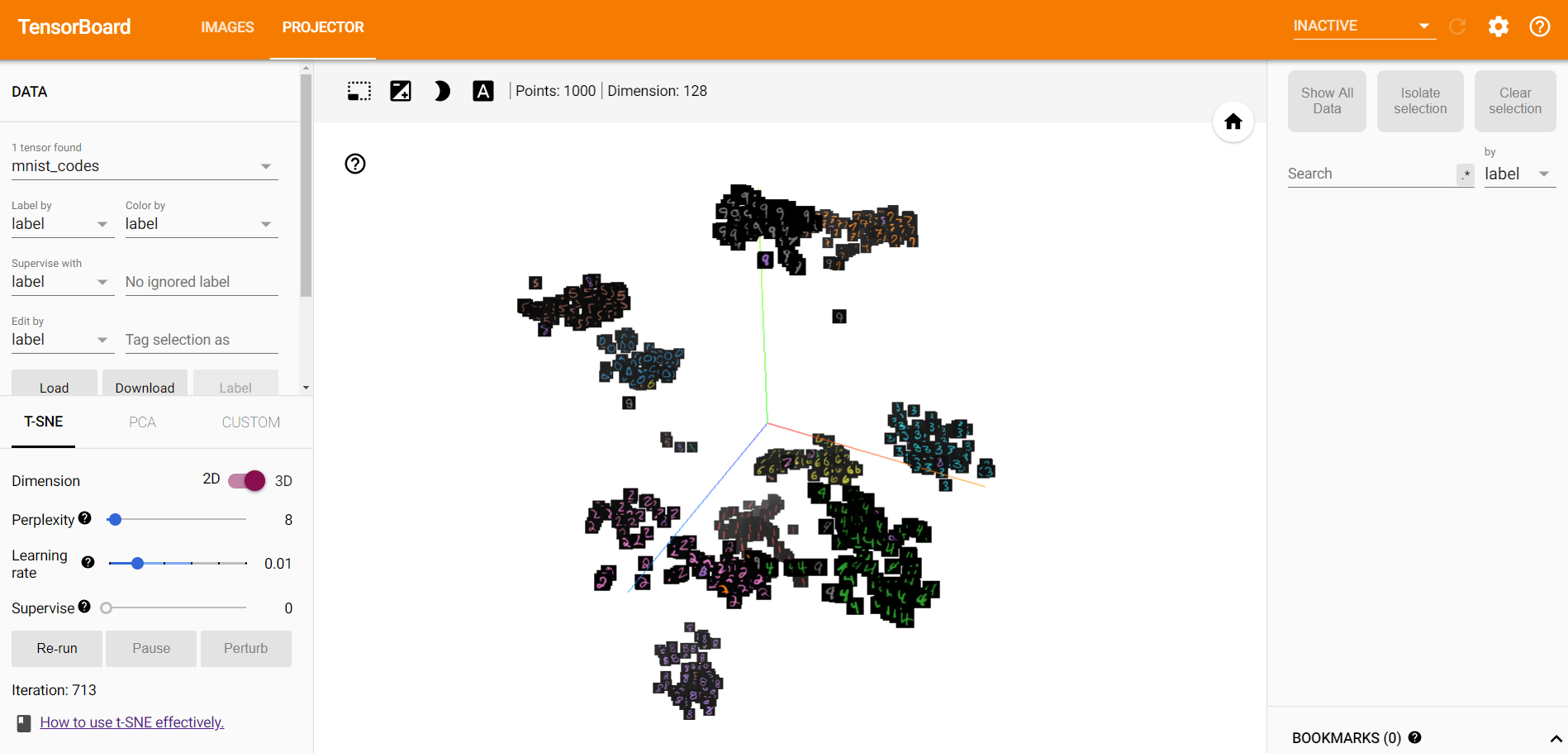
- 训练一段时间后,模型得到的embedding参数,使用t-SNE可视化的图像。
- 可以得到以下结论
- 训练之后,不同类别的样本在空间中的可分程度更大,这说明triplet loss可以用于图像检索等任务中,一方面用于降维(本文中的28X28图像被降成了128维),另一方面可以使得不相似样本之间的距离更大。
- 相对于PCA,t-SNE在降维可视化过程中的效果更好。
- 在训练之后,PCA的主成分的表征能力增强了(可以看前三个主成分占所有主成分的百分比,由27%左右提升到了45%左右)。